Click the following link to download the PPT.
Monthly Archives: January 2014
Pract 4: Write a Lex program to count the number of vowels and consonants in a given string.
%{
#include<stdio.h>
int vowels=0;
int cons=0;
%}
%%
[aeiouAEIOU] {vowels++;}
[a-zA-Z] {cons++;}
%%
int yywrap()
{
return 1;
}
main()
{
printf(“Enter the string.. at end press ^d\n”);
yylex();
printf(“No of vowels=%d\nNo of consonants=%d\n”, vowels,cons);
}
How to Compile:
1. Save the file with .l extention. E.g. vowels.l
2. lex vowels.l
3. gcc –o objfile lex.yy.c
4. ./objfile
PLEASE ALSO SEE:
Pract 3: Study of Lex – A Lexical Analyzer Generator
Introduction
Lex is a program generator designed for lexical processing of character input streams. It accepts a high-level, problem oriented specification for character string matching, and produces a program in a general purpose language which recognizes regular expressions. The regular expressions are specified by the user in the source specifications given to Lex. The Lex written code recognizes these expressions in an input stream and partitions the input stream into strings matching the expressions. At the boundaries between strings program sections provided by the user are executed. The Lex source file associates the regular expressions and the program fragments. As each expression appears in the input to the program written by Lex, the corresponding fragment is executed.
The user supplies the additional code beyond expression matching needed to complete his tasks, possibly including code written by other generators. The program that recognizes the expressions is generated in the general purpose programming language employed for the user’s program fragments. Thus, a high level expression language is provided to write the string expressions to be matched while the user’s freedom to write actions is unimpaired. This avoids forcing the user who wishes to use a string manipulation language for input analysis to write processing programs in the same and often inappropriate string handling language.
Lex is not a complete language, but rather a generator representing a new language feature which can be added to different programming languages, called “host languages.” Just as general purpose languages can produce code to run on different computer hardware, Lex can write code in different host languages. The host language is used for the output code generated by Lex and also for the program fragments added by the user. Compatible run-time libraries for the different host languages are also provided. This makes Lex adaptable to different environments and different users. Each application may be directed to the combination of hardware and host language appropriate to the task, the user’s background, and the properties of local implementations. At present, the only supported host language is C, although Fortran. Lex itself exists on UNIX, GCOS, and OS/370; but the code generated by Lex may be taken anywhere the appropriate compilers exist.
Lex turns the user’s expressions and actions (called source in this memo) into the host general-purpose language; the generated program is named yylex. The yylex program will recognize expressions in a stream (called input in this memo) and perform the specified actions for each expression as it is detected. See below Figure.

For a trivial example, consider a program to delete from the input all blanks or tabs at the ends of lines.
%%
[ \t]+$ ;
is all that is required. The program contains a %% delimiter to mark the beginning of the rules, and one rule. This rule contains a regular expression which matches one or more instances of the characters blank or tab (written \t for visibility, in accordance with the C language convention) just prior to the end of a line. The brackets indicate the character class made of blank and tab; the + indicates “one or more …”; and the $ indicates “end of line,” as in QED. No action is specified, so the program generated by Lex (yylex) will ignore these characters. Everything else will be copied. To change any remaining string of blanks or tabs to a single blank, add another rule:
%%
[ \t]+$ ;
[ \t]+ printf(” “);
The finite automaton generated for this source will scan for both rules at once, observing at the termination of the string of blanks or tabs whether or not there is a newline character, and executing the desired rule action. The first rule matches all strings of blanks or tabs at the end of lines, and the second rule all remaining strings of blanks or tabs.
Lex Source Definitions
The general format of Lex source is:
{definitions}
%%
{rules}
%%
{user subroutines}
where the definitions and the user subroutines are often omitted. The second %% is optional, but the first is required to mark the beginning of the rules. The absolute minimum Lex program is thus
%%
(no definitions, no rules) which translates into a program which copies the input to the output unchanged.
Remember that Lex is turning the rules into a program. Any source not intercepted by Lex is copied into the generated program. There are three classes of such things.
1) Any line which is not part of a Lex rule or action which begins with a blank or tab is copied into the Lex generated program. Such source input prior to the first %% delimiter will be external to any function in the code; if it appears immediately after the first %%, it appears in an appropriate place for declarations in the function written by Lex which contains the actions. This material must look like program fragments, and should precede the first Lex rule. As a side effect of the above, lines which begin with a blank or tab, and which contain a comment, are passed through to the generated program. This can be used to include comments in either the Lex source or the generated code. The comments should follow the host language convention.
2) Anything included between lines containing only %{ and %} is copied out as above. The delimiters are discarded. This format permits entering text like preprocessor statements that must begin in column 1, or copying lines that do not look like programs.
3) Anything after the third %% delimiter, regardless of formats, etc., is copied out after the Lex output.
Definitions intended for Lex are given before the first %% delimiter. Any line in this section not contained between %{ and %}, and begining in column 1, is assumed to define Lex substitution strings. The format of such lines is name translation and it causes the string given as a translation to be associated with the name. The name and translation must be separated by at least one blank or tab, and the name must begin with a letter. The translation can then be called out by the {name} syntax in a rule. Using {D} for the digits and {E} for an exponent field, for example, might abbreviate rules to recognize numbers:
D [0-9]
E [DEde][-+]?{D}+
%%
{D}+ printf("integer");
{D}+"."{D}*({E})? |
{D}*"."{D}+({E})? |
{D}+{E}
Usage:
There are two steps in compiling a Lex source program. First, the Lex source must be turned into a generated program in the host general purpose language. Then this program must be compiled and loaded, usually with a library of Lex subroutines. The generated program is on a file named lex.yy.c. The I/O library is defined in terms of the C standard library.
The C programs generated by Lex are slightly different on OS/370, because the OS compiler is less powerful than the UNIX or GCOS compilers, and does less at compile time. C programs generated on GCOS and UNIX are the same.
UNIX. The library is accessed by the loader flag -ll. So an appropriate set of commands is lex source cc lex.yy.c -ll The resulting program is placed on the usual file a.out for later execution. To use Lex with Yacc see below. Although the default Lex I/O routines use the C standard library, the Lex automata themselves do not do so; if private versions of input, output and unput are given, the library can be avoided.
Language Processors – System Programming & Operating System by Dhamdhere – PPT
Click the following link to download a PPT of Language Processors – System Programming & Operating System by Dhamdhere.
Language Processors – System Programming & Operating System by Dhamdhere – PPT
Pract 2: System Calls (fork(), wait()) in C Language.
fork()
When the fork system call is executed, a new process is created which consists of a copy of the
address space of the parent. The return code for fork is zero for the child process and the process
identifier of child is returned to the parent process.
On success, both processes continue execution at the instruction after the fork call.
On failure, -1 is returned to the parent process.
fork() – Sample Code
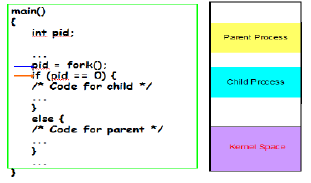
Implementation of fork() system call using C program.
Pract2a.c
#include <sys/types.h>
main()
{
pid_t pid;
pid = fork();
if (pid == 0)
printf(“\n I’m the child process”);
else if (pid > 0)
printf(“\n I’m the parent process. My child pid is %d”, pid);
else
perror(“error in fork”);
}
Commands: # gcc –o pr pract2a.c
# ./pr
*******************************************************************************
wait()
The wait system call suspends the calling process until one of its immediate children terminates. If the call is successful, the process ID of the terminating child is returned.
Zombie process—a process that has terminated but whose exit status has not yet been received by its parent process or by init.
pid_t wait(int *status); where status is an integer value where the UNIX system stores the value returned by child process.
Implementation of wait() system call using C program.
Pract2b.c
#include <stdio.h>
void main()
{
int pid, status;
pid = fork();
if(pid == -1)
{
printf(“fork failed\n”);
exit(1);
}
if(pid == 0)
{
/* Child */ printf(“Child here!\n”);
}
else
{
/* Parent */ wait(&status);
printf(“Well done Child!\n”);
}
}
Commands: # gcc –o pr pract2b.c
# ./pr
